这次我们用于演示的 XML 文本来自 W3Schools 的一个样例,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| <?xml version="1.0" encoding="UTF-8"?>
<breakfast_menu>
<food>
<name>Belgian Waffles</name>
<price>$5.95</price>
<description>Two of our famous Belgian Waffles with plenty of real maple syrup</description>
<calories>650</calories>
</food>
<!-- 省略中间的三个 food -->
<food>
<name>Homestyle Breakfast</name>
<price>$6.95</price>
<description>Two eggs, bacon or sausage, toast, and our ever-popular hash browns</description>
<calories>950</calories>
</food>
</breakfast_menu>
|
假定我们的任务是读取所有 food 节点的 name 属性的值,然后将它们存储到一个 List<string> 中。首先我们来用几种方式来实现这个需求。
使用 XmlDocument
¶
XmlDocument 算是一种“传统”的方式。它有两种“玩法”,一种是使用诸如 GetElementsByTagName 这样的方法,一点一点地找到我们需要的节点及其属性和内容;另一种是使用 XPath 表达式,一次性找到所有符合条件的节点。我们先来看看第一种方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public List<string> XmlDocument()
{
var doc = new XmlDocument();
doc.LoadXml(testXml);
return doc
.GetElementsByTagName("food")
.OfType<XmlNode>()
.Select(node => node["name"]!.InnerText)
.ToList();
// var names = new List<string>();
// foreach (XmlNode node in doc.GetElementsByTagName("food"))
// {
// names.Add(node["name"]!.InnerText);
// }
// return names;
}
|
Info
上面注释掉的代码是使用传统的 foreach 循环来实现的,这样写在旧版本的 .NET 中可能会更快一些,但是在 .NET 7 以来的新版本中,LINQ 的性能已经得到了很大的提升。对于常见的集合类型,LINQ 的性能已经和传统的 foreach 循环相差无几,甚至有时还更快,而且完全不会产生额外的 GC 压力。
然后我们还可以用 XPath 表达式来实现:
1
2
3
4
5
6
7
8
9
10
| public List<string> XmlDocumentXPath()
{
var doc = new XmlDocument();
doc.LoadXml(testXml);
return doc
.SelectNodes("//food/name")
.OfType<XmlNode>()
.Select(node => node.InnerText)
.ToList();
}
|
使用 Xml.Linq
¶
Xml.Linq 是一种更加现代的方式,它的 API 设计更加友好,使用起来也更加方便。我们可以这样来实现:
1
2
3
4
5
6
7
8
9
| public List<string> XDocument()
{
var doc = XDocument.Parse(testXml);
return doc
.Root
.Elements("food")
.Select(node => node.Element("name")!.Value)
.ToList();
}
|
XDocument 同样可以使用 XPath 表达式来实现,但是这里我们就不演示了,因为 XDocument 的 API 设计已经足够友好,不像是 XmlDocument 那样使用 XPath 表达式会显得更加简洁。
使用 XmlReader
¶
XmlReader 是一种基于流的方式,它的操作并不简单,但是效率极高。我们可以这样来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public List<string> XmlReader()
{
using var stringReader = new StringReader(testXml);
using var xmlReader = System.Xml.XmlReader.Create(stringReader);
var res = new List<string>(8);
while (xmlReader.Read())
{
if (xmlReader.IsStartElement() && xmlReader.Name == "name")
{
res.Add(xmlReader.ReadElementContentAsString());
}
}
return res;
}
|
使用 Regex
¶
因为我们的任务过于简单,要解析的 XML 文本内容也很纯粹,所以我们还可以使用正则表达式来实现:
1
2
3
4
5
| public List<string> Regex()
{
var matches = Regex.Matches(testXml, @"<name>(.*?)</name>");
return matches.Select(match => match.Groups[1].Value).ToList();
}
|
使用传统的字符串方法
¶
最后,我们还可以使用传统的字符串方法来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public List<string> StringOps()
{
var res = new List<string>(8);
int cur = 0;
while (true)
{
// 找到下一个 <name> 节点
int idx = testXml.IndexOf("<name>", cur);
// 如果找不到,说明已经找完了
if (idx < 0)
break;
// 找到对应的 </name> 节点
int end = testXml.IndexOf("</name>", idx + 6);
res.Add(testXml.Substring(idx + 6, end - idx - 6));
// 从下一个节点开始继续找
cur = end + 7;
}
}
|
提前剧透一下,这个方式的效率非常低,远低于其他几种方式。因此,我们还有一个杀手锏:Span<T>。
使用 Span
¶
Span<T> 是 C# 7.2 引入的一个新特性,它可以让我们更加高效地操作内存。我们可以这样来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public List<string> SpanOps()
{
var res = new List<string>(8);
var span = testXml.AsSpan();
while (true)
{
int idx = span.IndexOf("<name>");
if (idx < 0)
break;
int end = span.Slice(idx + 6).IndexOf("</name>") + idx + 6;
res.Add(span.Slice(idx + 6, end - idx - 6).ToString());
span = span.Slice(end + 7);
}
return res;
}
|
性能测试
¶
现在我们就可以来测试一下这几种方式的性能了。我们使用 BenchmarkDotNet 来进行测试。结果如下:
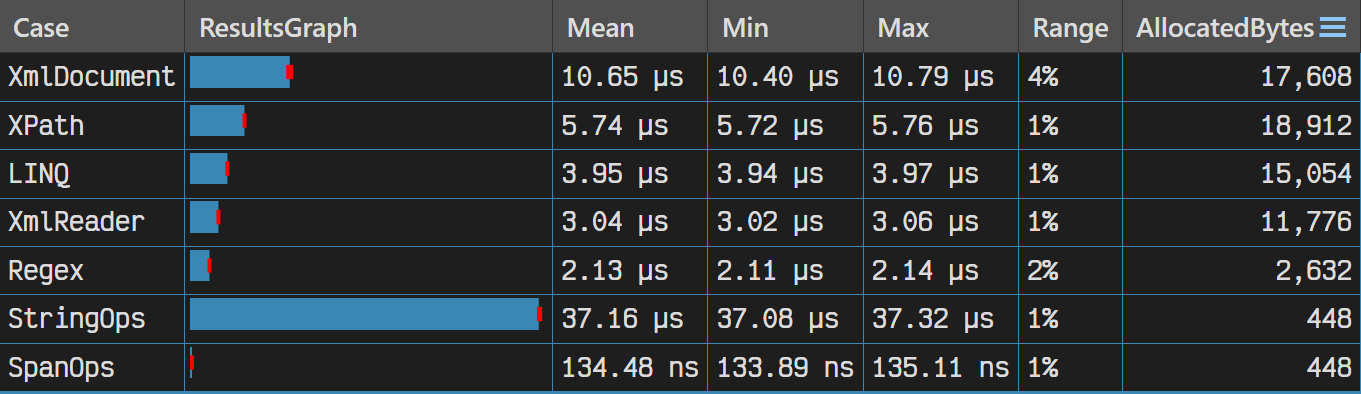
怎么样,大家领教了 Span 的威力了吗?它一骑绝尘,已经进入纳秒的境界了。所以我们可以得出结论:
- 如果我们要获取的内容并不复杂,我们完全可以使用正则表达式来抓取想要的内容,而不是死板地解析 XML 文档
- 当较为复杂时,我们还是需要借助传统的方式进行读取。它们的性能关系为:
XmlReader > XDocument > XmlDocument - 从实用性的角度考虑,
XDocument 比 XmlReader 及 XmlDocument 都更加实用,速度比传统的 XmlDocument 快,又并不显著逊于 XmlReader,所以应该是我们在大多数情况下的最优选项 - 使用
Span 可以显著优化性能,尤其是我们需要频繁对字符串进行 IndexOf、SubString 等操作时
